
宏观量化笔记1:线性模型不是万能模型
作者:Yaqi的宏观策略观点
题图:Yaqi的宏观策略观点的微信公众号
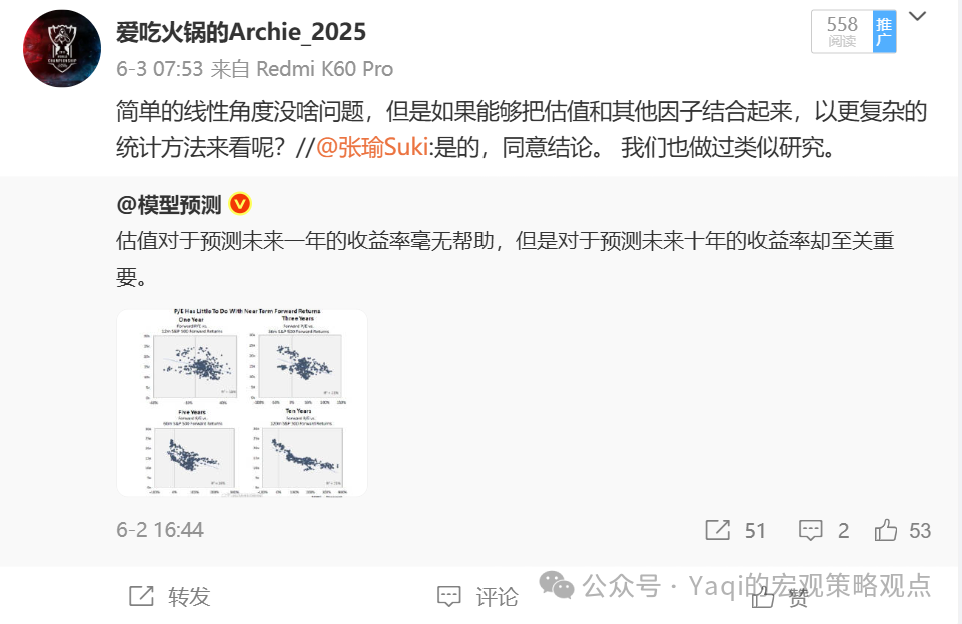
这是我自己的微博上面的一个转发评论。原博是截图了一篇国外的研报,通过线性模型的方法来说明美股PE对SPX未来一年的回报没有解释性,但是对SPX未来10年的回报有解释性。
我当然认可线性模型简单易懂好用,在多年的工作中也做了数不胜数的线性模型,来看看哪些因子对资产价格/经济数据有解释/预测作用,但我还是得说线性模型不是完美的模型,它的局限已经写在它的名字中了——“线性”。(当然我就不用说在实际运用过程中,有多少人是按照统计学的标准要求来使用线性模型的了,包括因子的stationarity 和 因子之间的 collinearity )
实际上从我自己的观察来看,资产价格和因子之间的关系更多的是非线性的而不是线性的。还是以美股估值和美股回报来看,举一个很简单的例子,假设我们是处于美股盈利增速的上升周期,那高估值和美股的1年内的回报很有可能是正关联的;但如果是处于美股盈利增速的下行周期,那高估值和美股的1年内的回报很有可能是负关联的;又例如都是对非农数据高于预期的反应,取决于数据公布前的市场 positioning的情况和数据高于预期的程度,市场可以呈现risk-off,也可以呈现risk-on。在众多类似的例子中,因子和资产价格的关系,更像是condition on 因子 X1 = A & X2 = B, 资产 Y= C 这样的非连续性,非线性的关系。 如果仅仅因为跑了几个简单的OLS效果不好,就断言某个或者某些因子不好用,我认为其实是有失偏颇的。因为可能不是东西不行,而是你用这个东西的方式方法有问题。
线性模型的另一个问题就是比较难处理大量的因子,这里面一般有三个问题:1)因子数量本身。线性模型处理几个,十几个因子也许还可以,但如果因子是几百个或者上千个呢?它这个模型本身就不适合处理这么多因子。2)因子之间的collinearity 3)因子量纲不一样,需要清洗和标准化,但我自己的看法是存在洗掉一定信息的可能性。
当然,大家已经使用了各种方法来给线性模型打补丁:1)针对线性模型的”线性“的局限性,在线性模型的基础上引入penalty等,构建类似于ridge OLS model,使得模型能够在一定程度上应对非线性关系。2)针对因子的数量过多和因子之间的collinearity的问题,使用PCA等方式来降维,或者要么把多个因子通过各种数学方法揉合成一个因子。
这些我都理解,也觉得没有问题。但是为啥就非得要用线性模型不可呢?咱又不是说没有其他模型可用了,现在不是已经有众多的成熟的机器学习和深度学习模型了吗,而且scikit-learn就直接提供这种免费便捷的模型包,里面的模型经过业界和学术界验证,而且会及时更新,这些模型既适用于非线性关系,也可以处理多维数据,它就不香吗。我感觉不停的给线性模型打补丁去fit非线性的现实世界的关系,就好像给战马配上加特林机关枪上战场一样,那你都已经有坦克了为啥不直接上坦克呢。
当然,我也理解大家对于机器学习和深度学习模型的担忧,确实存在一定的黑盒子的问题,虽然大家用”纯黑盒子“的ChatGPT和Deepseek毫无心理障碍,但是一旦到了投资领域就变得小心谨慎了。但我有两点想法:1)机器学习模型,例如基于决策树的模型,实际上能够给出一定的解释力度,告诉你哪些因子是重要的。2)用非线性的模型去拟合和预测非线性的宏观经济和市场现实,逻辑上是应该效果更好的,你是愿意接受一个70%透明的夏普1.5的机器学习模型,还是接受一个100%透明的夏普0.5的线性模型?(仅限于宏观策略模型,不考虑基于市场套利和统计套利的中高频模型,因为后者不需要宏观经济学逻辑支撑)
免责声明:
您在阅读本内容或附件时,即表明您已事先接受以下“免责声明”之所载条款:
1、本文内容源于作者对于所获取数据的研究分析,本网站对这些信息的准确性和完整性不作任何保证,对由于该等问题产生的一切责任,本网站概不承担;阅读与私募基金相关内容前,请确认您符合私募基金合格投资者条件。
2、文件中所提供的信息尽可能保证可靠、准确和完整,但并不保证报告所述信息的准确性和完整性;亦不能作为投资决策的依据,不能作为道义的、责任的和法律的依据或者凭证。
3、对于本文以及文件中所提供信息所导致的任何直接的或者间接的投资盈亏后果不承担任何责任;本文以及文件发送对象仅限持有相关产品的客户使用,未经授权,请勿对该材料复制或传播。侵删!
4、所有阅读并从本文相关链接中下载文件的行为,均视为当事人无异议接受上述免责条款,并主动放弃所有与本文和文件中所有相关人员的一切追诉权。
