
作者:建榕量化研究
题图:建榕量化研究微信公众号
摘要
海外分析师不断增加对A股上市公司的覆盖数量
S&P Global 的分析师预期数据库主要涵盖三类表,分别是核心表(Core Tables)、数据表(Data Tables)和引用表(Reference Tables)。
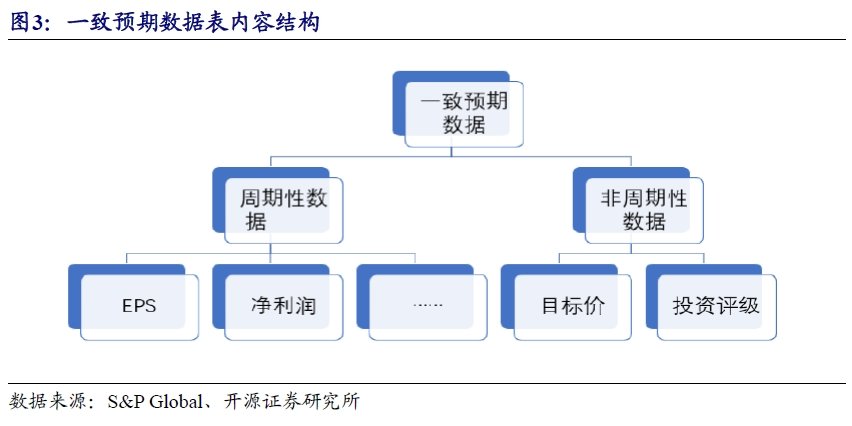
分析师一致预期数据库中,主要包含周期型数据(Periodic)和非周期型数据(Non-Periodic)两大类。周期型数据主要是关于上市公司财务报表中各维度指标的预测,常见的指标有EPS、净利润和ROE等。非周期类数据主要涵盖上市公司的目标价预测和投资评级等。
当前外资分析师针对A股上市公司盈利预测数据的覆盖范围逐年提升,以EPS(GAAP)为例,2023年度4月财报披露期最高样本覆盖数量为1754家,约占全市场A股数量1/3左右。
分析师预期数据的官方衍生指标样本数量分布不够均匀
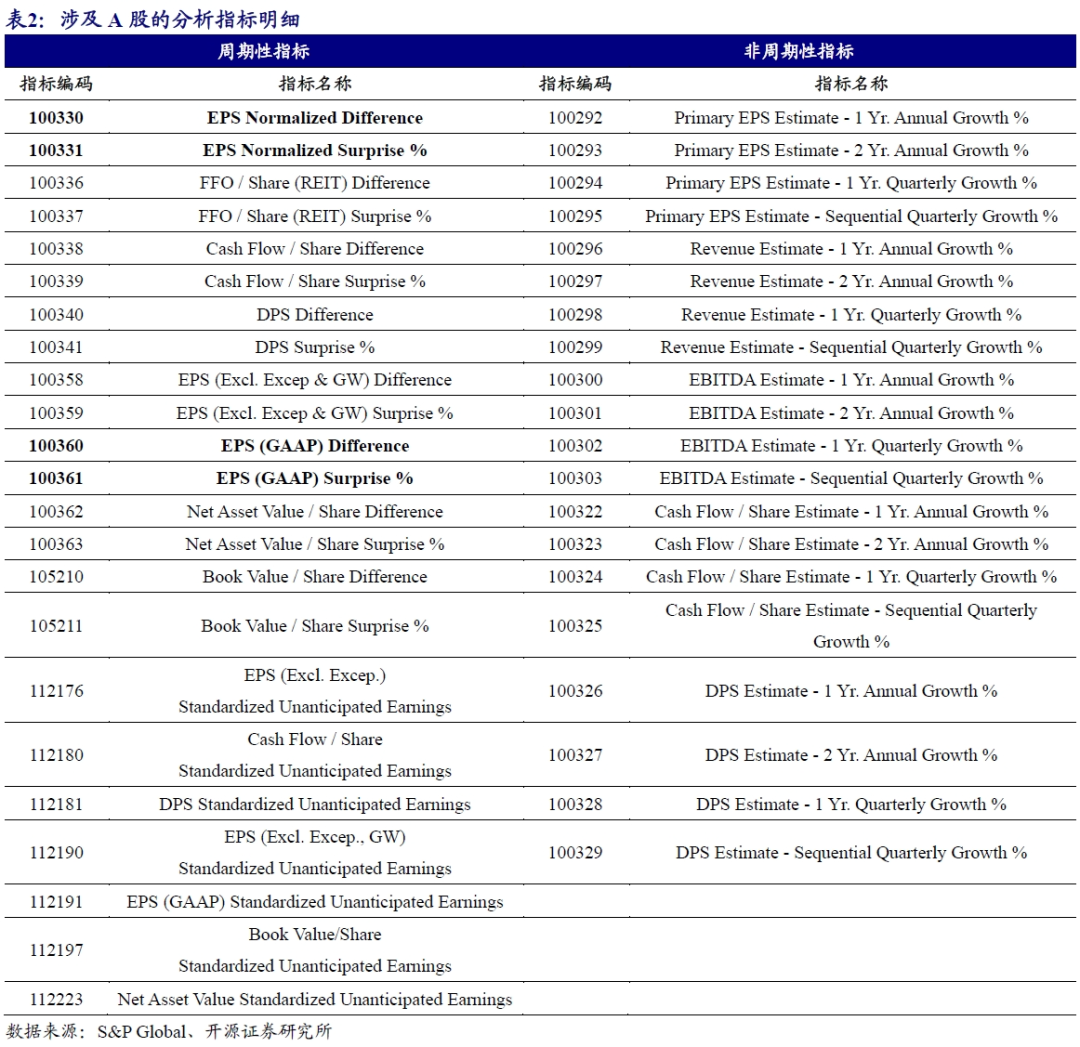
一致预期分析表中包含83个指标,其中43个指标在A股有对应的数值结果。其中周期性指标有23种,非周期性指标20种。根据分类统计结果,数据差值(Difference)、惊喜(Surprise)和标准化未预期盈余(Standardized Unanticipated Earnings)是周期性的指标,而增长率(Growth)则为非周期性指标。
官方衍生指标中收益稳定性相对占优的为EPS Normalized Difference。整体而言,EPS差值指标(EPS Difference)优于惊喜指标(EPS Surprise)。
多维度分析师预期数据融合能有效提升选股表现
盈利预期调整因子(ECA)全区间内RankIC均值仅为2.14%,年化RankICIR为1.11。目标价收益率因子(TPR)RankIC均值为2.27%,年化RankICIR为1.09。在回测前期,预测效果优异,中期波动增大,胜率下降,后续有所恢复,最近一年又开始转弱。投资评级变动因子(RTV)RankIC均值为1.72%,年化RankICIR为1.34。2022年以来累计RankIC出现较大回撤,但近期开始转好。
复合分析师因子(MA)RankIC均值为2.36%,年化RankICIR为1.65。2022年9月后累计RankIC持续回撤了近一年时间,后续开始反弹转好。复合分析师因子多头端年化收益率为9.24%,多空超额年化收益率为7.11%,最大回撤为-7.84%,月度胜率约70%。
复合分析师因子在不同宽基指数中均有优异的增强效果。在超额收益率稳定性上,中证500指数的增强表现最优,收益波动比为1.59,但超额收益率回撤亦是最大水平,达到-10.46%。

无论是主动投资抑或量化研究,分析师预期数据始终是绕不开的话题。分析师预期数据既可以帮助我们判断上市公司业绩超预期与否,亦能辅助我们感知当前市场不同分析师对指定个股观点的变化趋势。
以往我们审视A股分析师预期数据的时候,更多是站在国内分析师视角,引用的数据均来自国内分析师的相关研究成果。随着A股市场重要性的与日俱增,优秀的上市公司体量逐渐增加,海外券商对A股上市公司进行分析覆盖的密度与频率也在逐步增加。
S&P Global 作为业内领先的基础数据提供商,凭借其丰富的数据覆盖、及时的数据更新和快速的服务响应,深受全球主流市场参与者的认可。本篇报告,我们尝试以S&P Global数据库中分析师预期数据为基础,从海外分析师视角来观察A股上市公司预期数据的结构、特征和表现。
本篇报告,我们尝试从四个方面进行展开。第一部分,我们针对S&P Global一致预期数据库的设计架构进行简要说明,尝试厘清各表之间的关联关系,便于定位我们所需数据。在此基础上,我们对海外分析师视角下的A股一致预期数据进行了描述性分析统计。第二部分,我们测试了S&P Global数据库中基于一致预期数据所构建的衍生因子的选股表现。衍生因子涵盖周期性和非周期性两个维度,在每个维度下面存在多种统计指标。第三部分,我们根据海外分析师针对A股上市公司提供的盈利预期、目标价和投资评级三类数据,构建了相应的选股因子,并分别测试了各自的选股表现。此外,我们对不同维度的分析师预期数据进行融合,构建了复合分析师因子,整体选股效果有所提升。第四部分,我们根据复合分析师因子构建了主流宽基指数增强策略,整体表现优异。
01
S&P Global预期数据概览
S&P Global 数据库整体设计理念轻量高效,很少有冗余信息存储,各表之间的关联关系通过架构图能够清晰了解掌握,但是无法所见即所得,为了找到所需的完整信息跨表匹配查询通常是必备操作。国内数据提供商设计理念则倾向于简单直观,其会在一张表中提供足够的数据字段,尽量让投资者在一张表中找到所需的信息。这么做的好处是数据直观易获取,但当表的数量非常多时,容易造成部分字段重复存储,耗费更多存储空间。到底哪种设计方案更优,根据使用场景的变化因人而异。
S&P Global 分析师预期数据库(S&P Capital IQ Estimates)作为一个透明的、高质量的、标准化的全球数据库,包括实时对全球上市公司进行投资评级的调整、目标价的修订、跟踪上市公司动态新闻或重大事项,以及基于分析师、经纪人和公司本身的预测、建模和分析。其估算数据主要来自研究报告、研究员和新闻稿。
1.1、数据结构
从分析师预期数据表结构的设计来看,其主要包含三类表,分别是核心表(Core Tables)、数据表(Data Tables)和引用表(Reference Tables)。
核心表格提供了所有评估表所需的基础数据,许多字段都表示为整数,可以通过链接到数据表和引用表来进一步定义。数据表格提供了与每个估算表相关的数据。引用表提供了估算数据的额外细节,表名通常包含单词“Type”。引用表定义了核心表和数据表中的id,并允许您进一步检索描述该数据的文本项。引用表只能通过连接核心表和数据表来访问。

除了上述主要类型的表结构外,S&P Global中还存在一类数据表,即基础文件(Base Files),基础文件是所有其他数据集的基础。这些基础文件将所有数据集中的公司、证券、股票和其他基本对象联系起来。
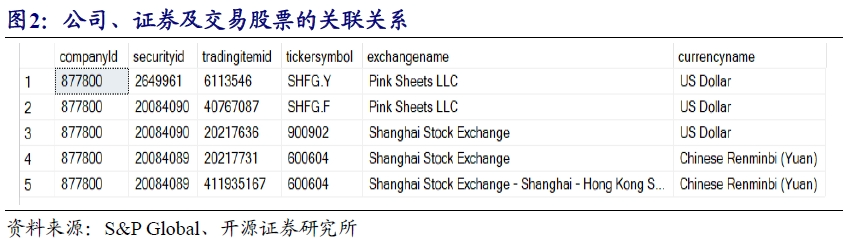
由于S&P Global数据涵盖全球主流交易市场,面向多维度资本市场,通常存在的一个场景是某个综合类型的集团,旗下包含多个上市公司和非上市公司主体,在不同交易所同时有多种类型的金融产品在交易,如证券、债券等。
以上海市北高新集团为例,如何通过跨表查询找到该集团对应的在A股上市的公司的相关信息,而非在其它交易所交易的其它类型标的,便成了一件关键的事情。可以看到,上海市北高新集团在上海交易所交易的证券有三种,不仅有最基础的A股上市公司,还有基于美元交易的B股和沪股通标的,而tradingItemId是唯一能识别彼此差异的字段。
1.2、数据内容
当前S&P Global数据库中关于分析师预期数据主要包含以下五张表,分别为一致预期数据(Consensus Estimates Data, CED)、明细估计数据(Detail Estimates Data, DED)、分析师覆盖数据(Analysts Coverage Data, ACD)和公司指引数据(Company Guidance Data, CGD)以及基于原始估计数据衍生得到的一致预期分析数据(Consensus Analysis Data, CAD)。
一致预期数据(CED)通过对不同分析师的预测做整理计算,提供了对一家上市公司的总体估计,和许多不同数据点的历史一致预期估计值。
明细估计数据(DED)提供特定交易主体或公司分析师级别的历史和当前估计值,这些估计值反映了个别分析师的研究或分析成果。每个分析师和经纪人都被分配了唯一的标识符以便我们能够随时跟踪个别分析师和独立的经纪商。
分析师覆盖数据(ACD)表明了哪些经纪商提供了哪家公司的覆盖研究。该表通过将经纪商和分析师与公司联系起来,提供了经纪商和分析师对公司研究的历史信息。经纪商和分析师覆盖的时间长短能够辅助我们判断他们对相关公司的了解程度。
公司盈利指引数据(CGD)提供了上市公司对其未来盈利或亏损的估计,这些信息分布在业绩报告、新闻稿或业绩说明会中。上市公司指引是一个强有力的指标,分析师和投资者对其关注非常密切,通常能够影响分析师的推荐行为和投资者的决策。
一致预期分析数据(CAD)以一致预期估计数据为基础,计算出衡量公司业绩相对应计项目的历史趋势。一致预期分析数据提供了不同的增长率指标和不同的惊喜指标,这些数据反映了公司当前情况相对于市场预期的表现。
以一致预期数据为例,在S&P Global数据库中,该表主要包含周期型数据(Periodic)和非周期型数据(Non-Periodic)两大类。在每个大类下面存在许多具体的指标,大概的框架结构如图3 所示。
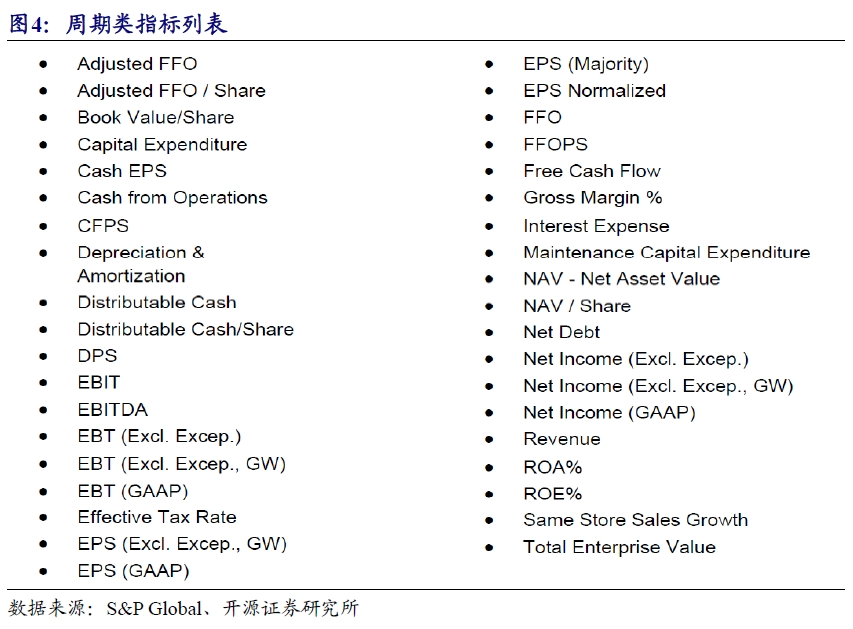
周期型数据主要是关于上市公司财务报表中各维度指标的预测,常见的指标有EPS、净利润和ROE等。相同指标下面亦存在不同统计口径,如EPS总共有四种计算模式。
非周期类数据主要涵盖以下几项,其中关于上市公司的目标价预测和投资评级是大家最常见的类型。

1.3、数据概览
在对S&P Global数据结构和内容进行初步介绍后,我们尝试基于S&P Global数据库中的一致预期数据(CED)表进行多维度描述性统计分析。由于篇幅所限,其他表格内容暂不展开。
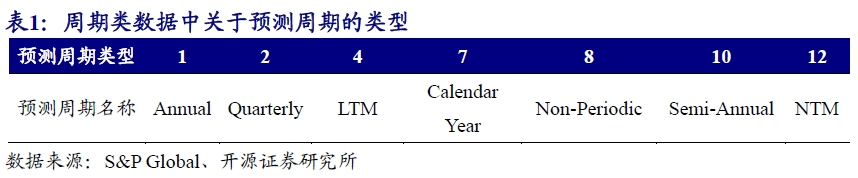
在S&P Global数据库中,针对上市公司财务表现进行预测的数据涵盖了季度预测、半年度预测、年度预测以及未来12个月预测等多种周期类型。为了避免混淆,在后续实际使用过程中,我们使用数据覆盖数量最多的年度预测值进行相关统计。对于非周期类数据,我们没有选择顾虑。
我们选取市场上关注度最高的三个指标进行介绍说明,分别是EPS(GAAP)、目标价和投资评级。EPS(GAAP)作为周期类数据的代表,目标价和投资评级属于非周期类指标。为了避免赘述,后续我们在部分结果上仅针对单一指标进行展示,如无特别说明,默认以EPS(GAAP)为例。数据统计区间为2010年1月到2023年12月。
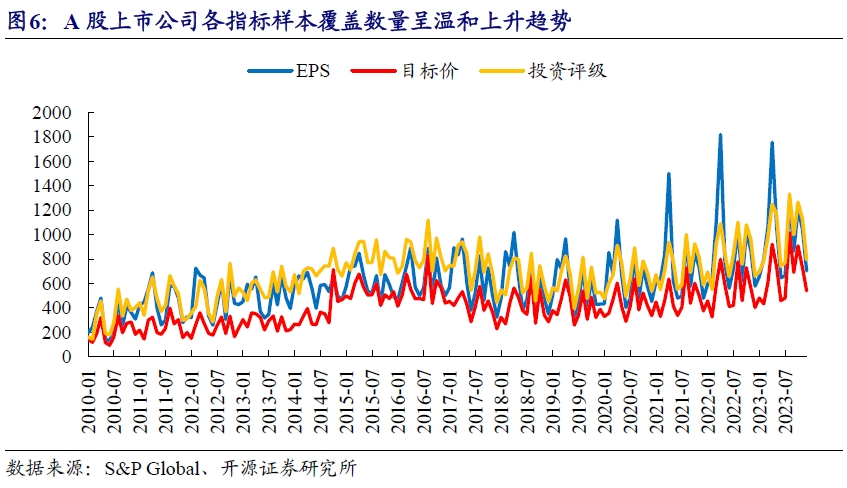
我们绘制了A股市场中主流宽基指数的样本覆盖情况,随着股票池市值的增加,样本覆盖度也在相应提升。沪深300指数成分股覆盖度最高,最新一期接近50%。中证1000指数成分股处于较低水平,平均值约20%,财报披露高峰期覆盖度约40%。全市场个股覆盖度约20%左右。

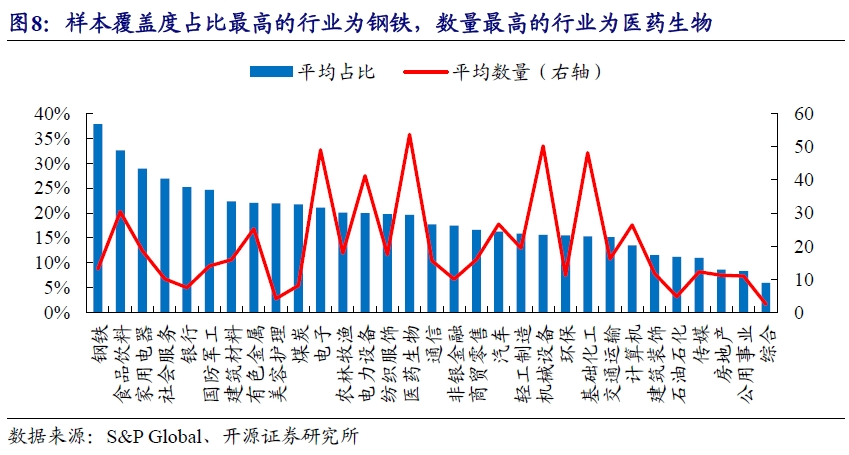
我们根据最新的申万行业分类标准,统计了过去十年间(2014年2月以来)外资分析师在不同行业中的个股平均覆盖数量和占比。钢铁、食品饮料和家用电器等行业外资覆盖的个股平均占比较高,医药生物、机械设备和电子等行业覆盖个股的平均数量较多。
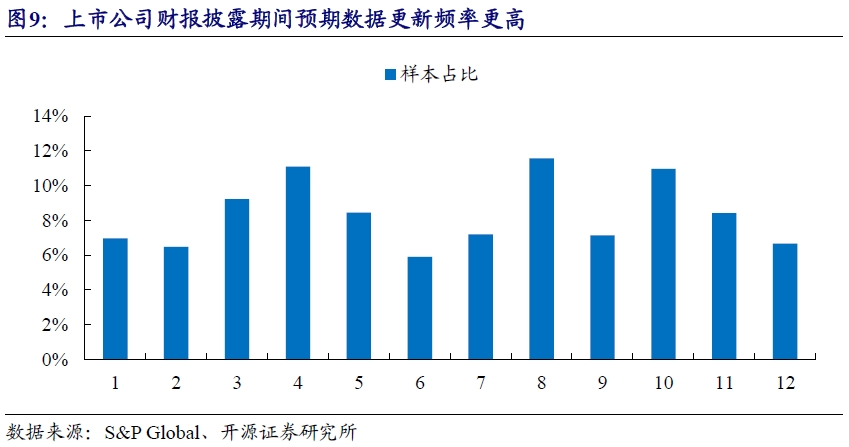
分析师对上市公司预期数据的更新通常和上市公司财报的披露节奏高度相关,从图6样本覆盖度图表中的锯齿形状也能一窥一二。可以看到,在A股上市公司财报密集披露的3月、4月、8月和10月四个月份,外资分析师针对上市公司相关预期指标进行调整的频率高于全年均值。
02
官方衍生数据测试
上文数据概览部分,我们仅针对分析师一致预期数据的样本覆盖及更新情况做了梳理,但对具体数据表现并未有介绍。本节,我们尝试更进一步,对分析师预期数据的相关衍生指标进行选股表现测试。
2.1、指标明细
S&P Global数据库的一致预期分析表中(CAD)计算了一些衡量公司业绩相对于应计项目的历史趋势的数值,其可以用来刻画分析师对相关个股预期值的变化情况,是衡量公司未来表现的重要指标。
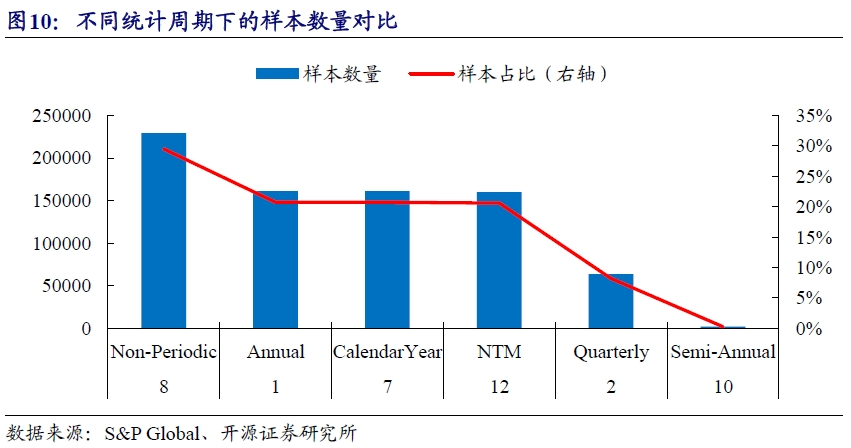
在进行测试之前,我们统计了一致预期分析表中在不同统计周期下的A股样本数量占比。可以看到,非周期类的计算指标占比最高,占比约30%,其次为年度统计结果占比约21%,占比最少的为半年度统计指标,仅约0.3%。
周期类指标和非周期类指标的差异主要体现在时间戳的区别上。周期类指标数据的更新主要对应四类时间戳,分别为effectiveDate、toDate、periodEndDate和advanceDate,非周期类数据仅有effectiveDate和toDate两个时间字段。简单概括,effectiveDate对应预测数据的生效日期,toDate对应预测数据的失效日期,periodEndDate表示预测数据对应的报告期,advanceDate表示实际数据披露的日期。根据时间戳定义可知,周期类指标涉及数据更新每次都需要指定报告期,而非周期类指标没有这个要求,其持续滚动更新。
上述从总量维度展开,下面我们尝试从具体指标维度来进行分析。根据A股的映射结果,当前S&P Global数据库一致预期分析表中包含83个指标,其中43个指标在A股有对应的数值结果。我们根据指标所属类型将指标分为周期性和非周期性两类,其中周期性指标有23种,非周期性指标20种,具体如表2所示。根据分类统计结果,数据差值(Difference)、惊喜(Surprise)和标准化未预期盈余(Standardized Unanticipated Earnings)是周期性的指标,而增长率(Growth Rate)则为非周期性指标。
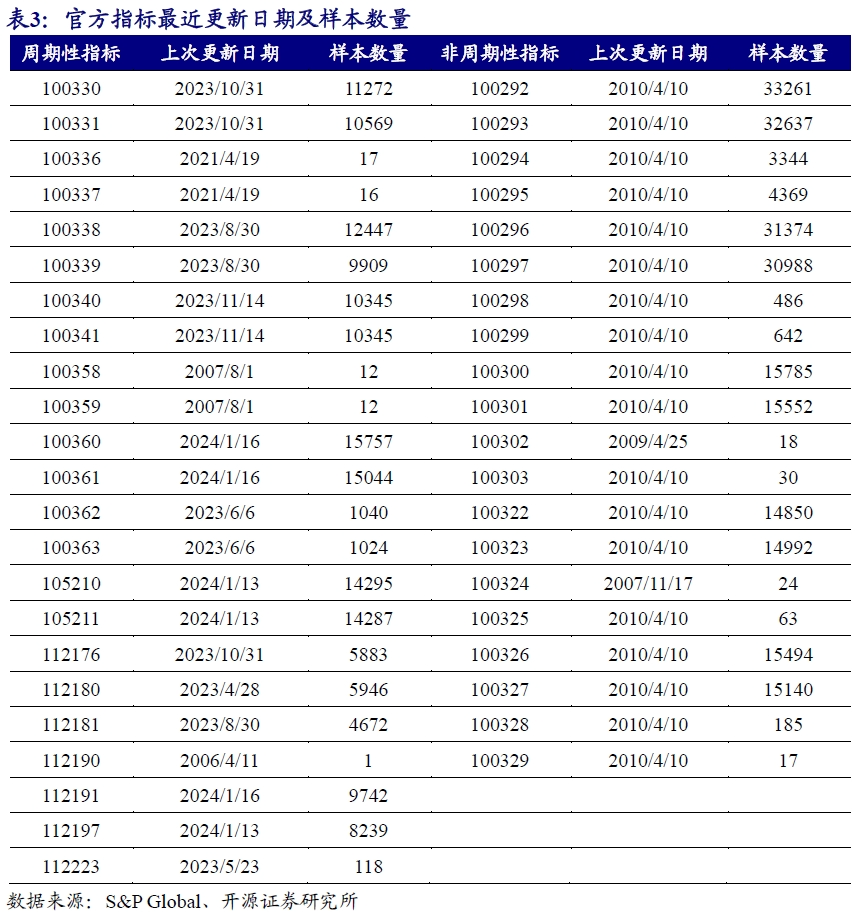
上述列表中的字段虽然都涉及A股,但部分字段计算的数据数量过少,不足以在截面上进行回测,同时部分字段数据最近的更新日期过于久远而无法用来评估当下表现。我们按照周期性和非周期两类标签,分别统计了不同指标对应的上次更新日期以及样本数量,其中周期类指标的样本数量按照年度口径(Annual)进行统计。
2.2、指标表现
在进行数据测试前,我们排除了所有非周期类的指标,因为上次更新日期过于久远。对于周期类指标,部分指标样本数量依然很难达标。需要注意的是,在一致预期分析表中,当指标按照年度进行统计时,一年仅有四个值,导致数据比较稀疏,不太适合进行回测。最终,我们根据数据更新的频率和样本数量,选取了四个季频更新的指标进行说明。针对季度更新的数据,我们按照前值填充的方法将其转变为月频的信号。在进行回测前,我们对初始数据进行预处理,剔除新股、ST股、停牌股等。
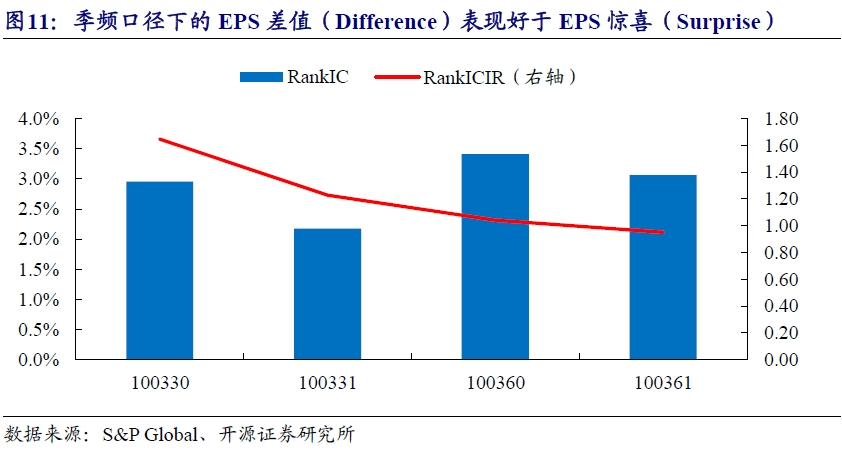
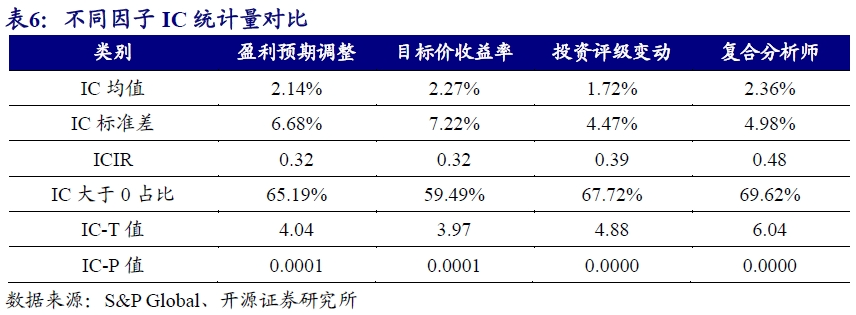
测试期内,四个指标均有一定的选股区分度,其中收益显著性表现相对占优的为100360,即EPS(GAAP) Difference,RankIC均值为3.41%,收益稳定性相对占优的为100330,即EPS Normalized Difference,年化RankICIR为1.65。整体而言,在不同统计口径下,差值指标(EPS Difference)优于惊喜指标(EPS Surprise)。
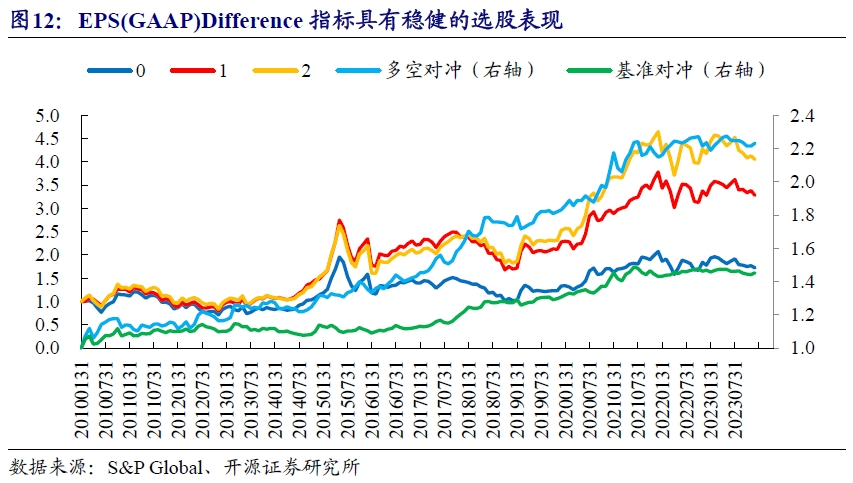
我们以相对表现占优的指标100360(EPS (GAAP) Difference)为例进行分组收益绘制。由于样本数量较少,我们仅分三组进行展示。从测试结果可知,指标100360从长期来看多头端具有稳健的选股表现,多空超额收益持续向上。
03
一致预期自定义因子构建
前文我们测试了S&P Global数据库中自带指标在A股的选股表现,但囿于样本数量和更新频率较低,导致在进行较高频率的调仓选股时面临一定的障碍。在本节,我们尝试从上市公司财务指标一致预期值、目标价一致预期值和投资评级一致预期值三个维度出发,自定义构建相关的因子值。
在S&P Global数据库中,由于财务指标存在多种统计口径,这里仅选取通用会计准则下的EPS(GAAP)年度预测值进行说明。上市公司财务指标的一致预期数据通常会包含当年、次年和两年后的预期情况,但是在S&P Global数据库中并没有显性指定财务数据的预测周期。我们根据一致预期数据中的生效日期(effectiveDate)和截止日期(periodEndDate)的间隔天数来识别针对不同年份的预测信息。在因子构建过程中,我们仅考虑预测周期为当年的一致预期数据。
3.1 盈利预期调整因子
我们通过对EPS预期数据在时序上进行Z-Score操作来构建盈利预期调整因子(Earnings Consensus Adjustment Factor,ECA),回看窗口期为过去12期数据。区别于简单计算前后两期盈利预期值的变动百分比(Surprise)或差值(Difference),时序标准化的处理方式能够有效平滑因子波动。对于财报真空期,我们采取前值填充的方式进行因子数据补全,并要求补全的跨度不超过4个月。
从测试结果来看,盈利预期调整因子自2021年初开始RankIC累计值开始走平,2023年甚至有一段时间持续下滑,导致全区间内RankIC均值仅为2.14%,年化RankICIR为1.11。
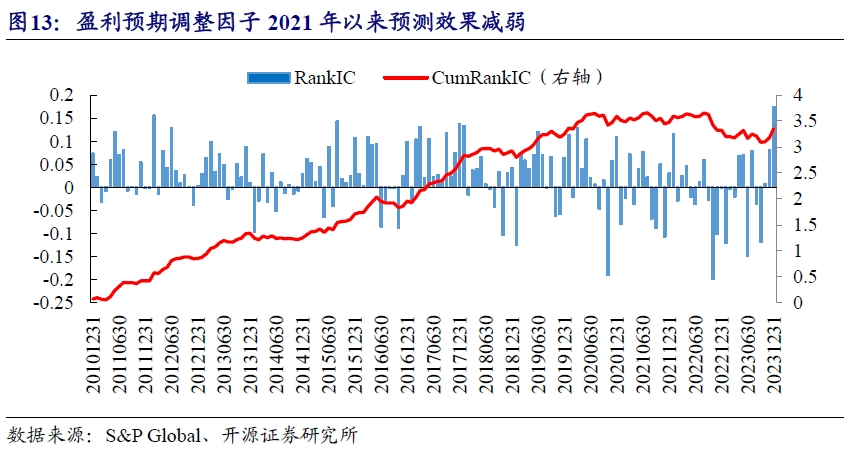
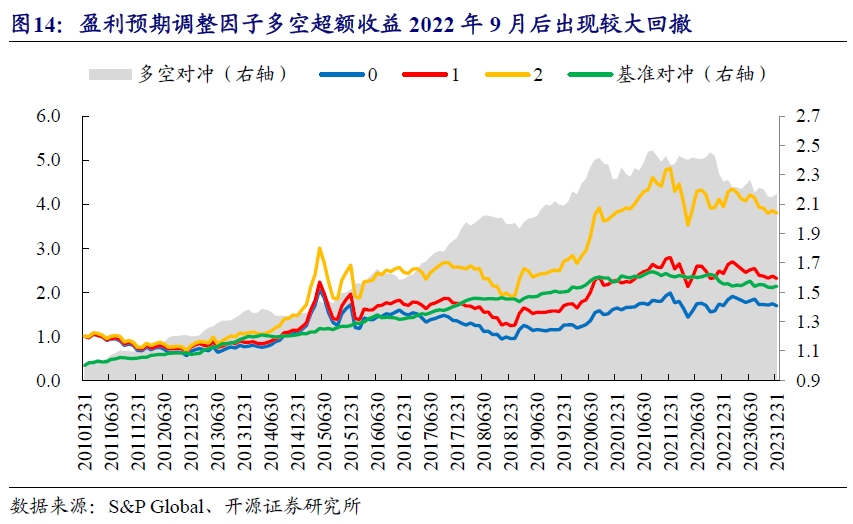
从分组收益来看,ECA因子在2021年7月之前,多空超额收益持续上行,但后期超额开始逐渐回撤,整体表现与A股市场成长风格2021年后退潮具有较高同步性。
3.2、目标价收益率因子
在S&P Global数据库中,上市公司目标价数据属于非周期类数据,不存在特定的窗口期。根据官方文档的介绍,目标价格数据覆盖0~18个月的范围,6~12个月的范围是最广泛使用的预测窗口期。
在计算目标价收益率时,我们按照上市公司当前时间实际价格与最新的分析师一致预期价格进行比较得到,具体计算如下:

目标价收益率因子RankIC均值为2.27%,年化RankICIR为1.09。在回测前期,预测效果优异,中期波动增大,胜率下降,后续有所恢复,最近一年又开始转弱。
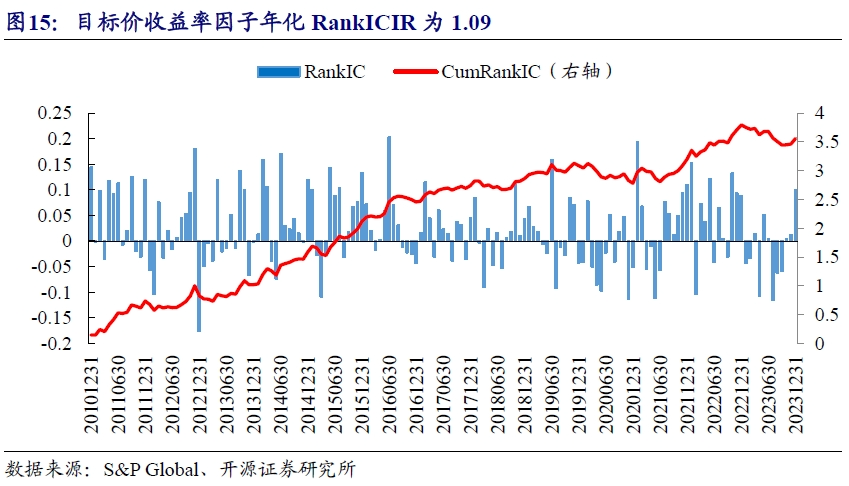
从分组收益来看,虽然三分组收益单调,但是超额收益在测试期内波动较大。在2019年下半年到2021年底,超额收益持续回撤,后期虽有反弹,但2023年下半年后又开始走弱。
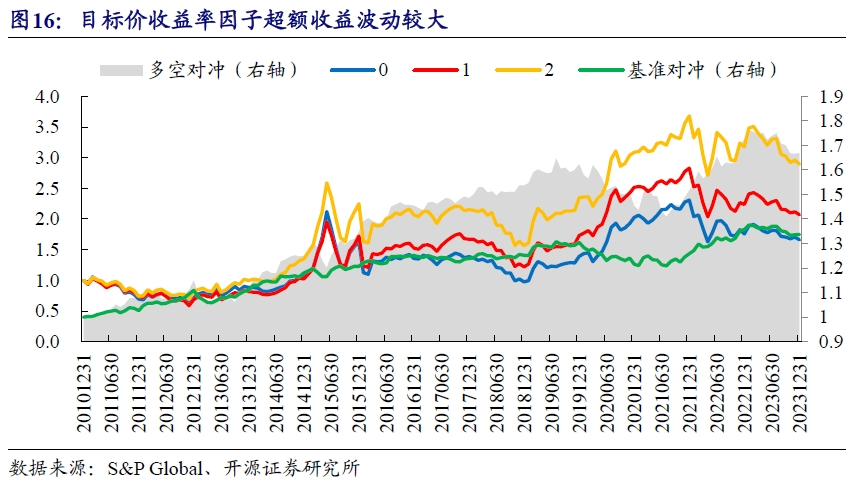
造成阶段性持续回撤的原因,我们认为与不同个股之间目标价收益率存在差异有关,分析师通常更愿意给予科技行业个股更高的收益空间,而对经营稳健的行业则相对保守。虽然通过市值行业中性化能一定程度上弱化这种差异,但并不足以完全消除。而前期受影响较小,我们猜想原因在于以前市场风格不像当前如此极化。
比如,贵州茅台由于营收稳定,目标价收益率分布在窄幅区间,反之,作为科技板块相关个股的代表中际旭创,历史上营收波动较大,目标价收益率的分布也更分散。当市场风格偏向蓝筹个股时,低目标价的收益率个股反而有望持续跑赢高目标价收益率个股,从而导致超额收益产生阶段性回撤。
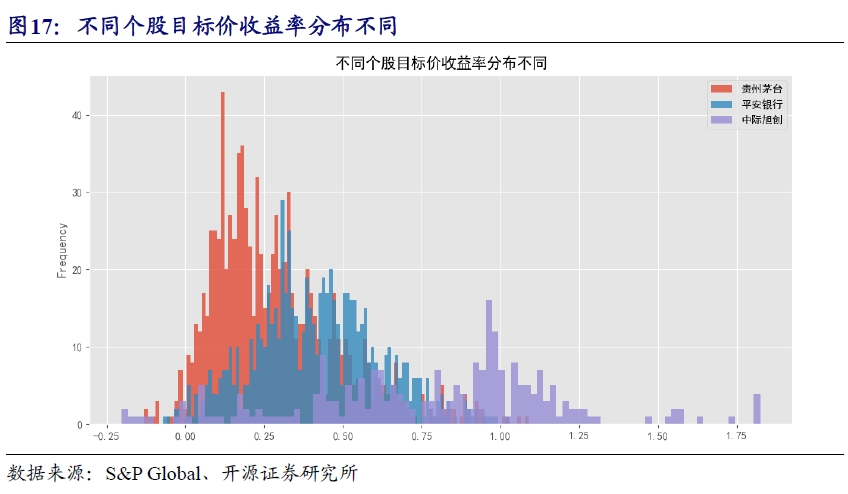
3.3、投资评级变动因子
当前,S&P Global一致预期数据库中包含的个股投资评级数据主要有五种类型,按照评级高低分别为买入(Buy)、卖出(Sell)、持有(Hold)、增持(Outperform)和减持(Underperform),少数个股没有投资评级,按照无意见(No Opinion)进行标注。
我们将不同个股的相同投资评级出现的次数进行加总,得到不同投资评级的分布情况。自2010年以来,买入推荐评级数量最多,占比约50%,其次为增持,占比约27%,减持和卖出的评级占比相对较低,分别为3.32%和4.07%。从评级分布来看,海外分析师看多的推荐次数显著高于看空的次数。
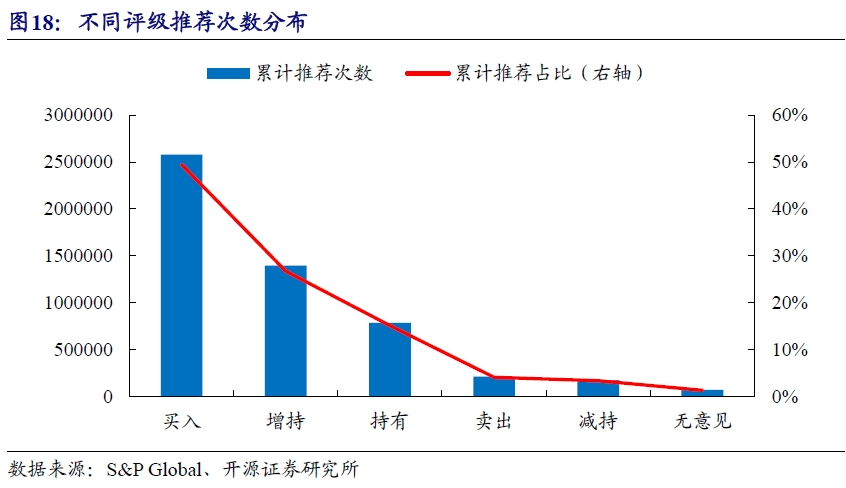
投资评级相比财务指标或目标价具有非连续性的特征,是一个个离散的变量,更适合作为事件来进行研究。但是事件驱动策略的缺陷在于仓位管理比较麻烦,为此我们尝试将离散事件因子化。
我们按照投资评级从高到低给各评级进行打分,其中代表最高投资评级的买入(Buy)有5分,代表最低评级的卖出(Sell)为1分,其他评级得分以此类推,其中无意见(No Opinion)赋为空值。对于每只个股,在每个时间节点,我们根据不同投资评级上的分析师推荐数量,汇总得到市场上不同分析师在该只个股上的投资评级的加权得分。
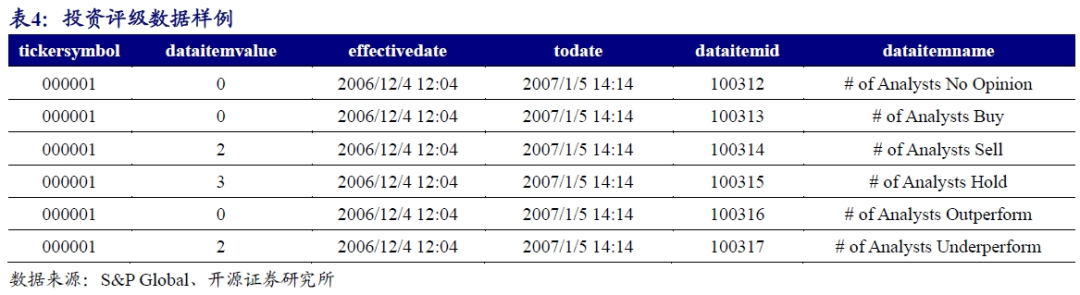
根据表4样例数据,当期(2006/12/4 12:04)股票000001的加权得分为:
(2 * 1 + 3 * 3 + 2 * 2) / (2 + 3 + 2) = 2.14
单纯在截面上进行分组测试,效果并不好。我们推测原因在于市场上的蓝筹白马股可能长期处于被分析师推荐买入或增配的状态,而市值偏低的个股更可能面临持有或减配的建议,如果直接对比不同个股截面的投资评级高低,容易造成审视偏差。
为了剔除不同个股的分析师偏好所隐含的差异,我们在计算得到每只个股每期的得分后,再在时序上进行标准化处理,生成最终的投资评级变动因子(Recommendation Type Variation Factor, RTV)。时序标准化处理的窗口为12期,在对缺失值进行前向填充时,要求跨度不超过4个月。
从测试结果来看,时序标准化处理后的投资评级变动因子RankIC均值为1.72%,年化RankICIR为1.34。2022年以来累计RankIC出现较大回撤,但近期开始转好。
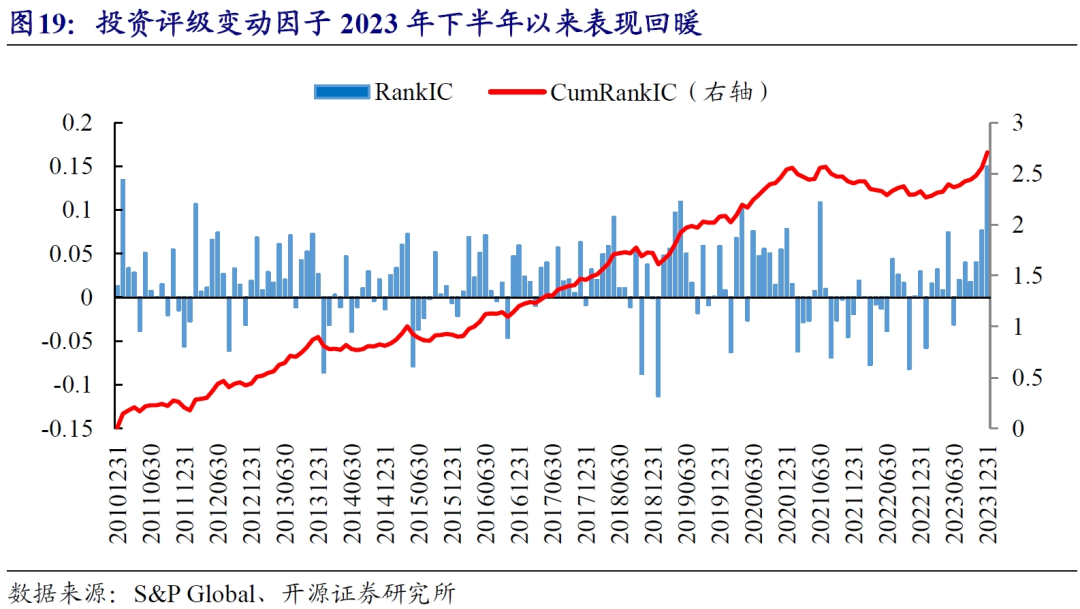
从分组收益来看,投资评级变动因子严格单调,且空头端具有更强的区分度,即市场投资者对评级下调个股的敏感度显著高于评级上调个股。
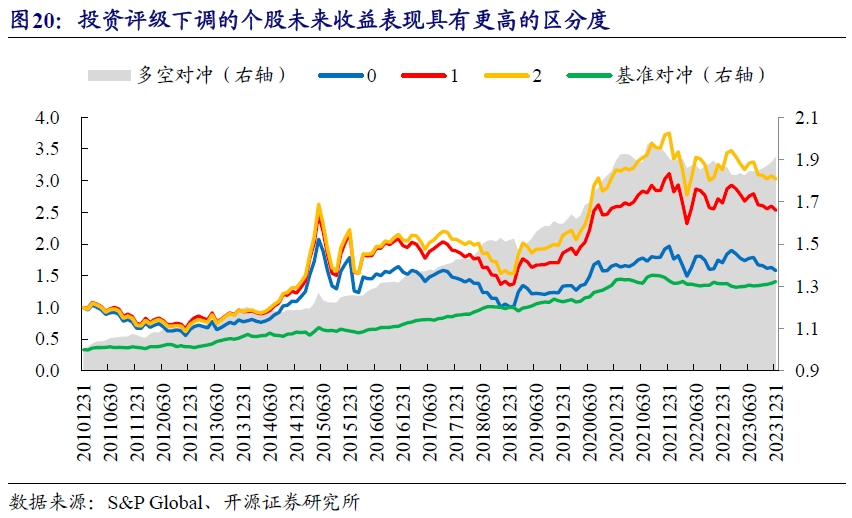
3.4、多维度合成
上文中,我们分别测试了分析师盈利预期调整、目标价收益率和投资评级变动三类数据在A股市场的表现。概括而言,三类因子的表现大体一致,但在部分时间段呈现各自的特点,如近一年盈利预期调整因子(ECA)多空超额收益持续回撤,目标价收益率因子(TPR)先回暖再下跌,而投资评级变动(RTV)因子先下滑再回暖。
不同的特征表现隐含着不同的信息。我们尝试将盈利预期调整、目标价收益率和投资评级变动三个维度的因子进行等权合成,以衡量分析师多维度观点的综合变化,定义为复合分析师因子(Merged Analyst Factor, MA)。
测试期内复合分析师因子RankIC均值为2.36%,年化RankICIR为1.65。2022年9月后累计RankIC持续回撤了近一年时间,后续开始反弹转好。
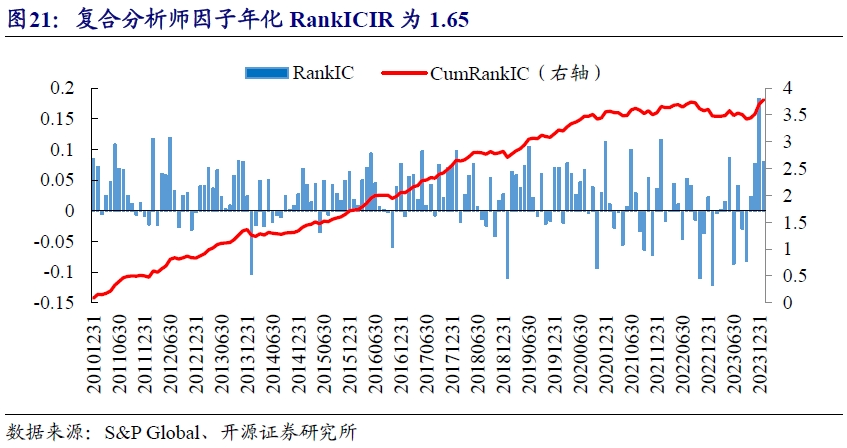
从分组收益来看,复合分析师因子在超额收益的稳定性上有明显提升,但遗憾的是近一年依然无法规避超额收益的回撤。
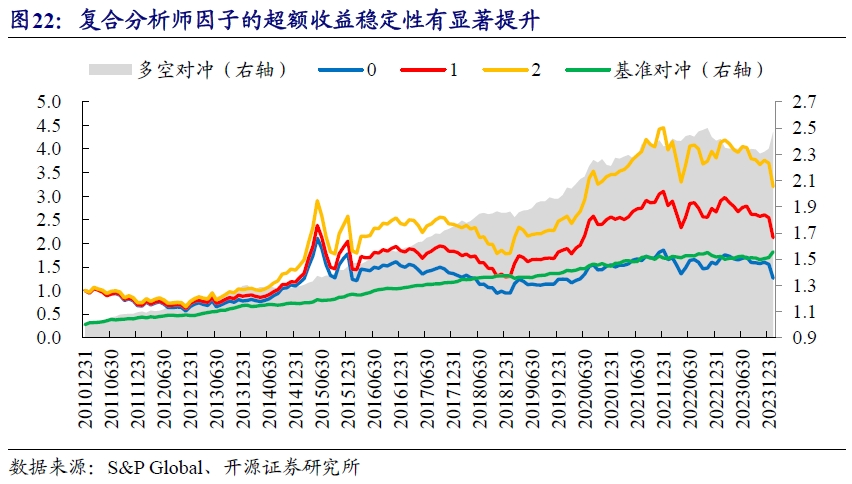
根据绩效统计结果,复合分析师因子多头端年化收益率为9.24%,多空超额年化收益率为7.11%,最大回撤为-7.84%,月度胜率约70%。
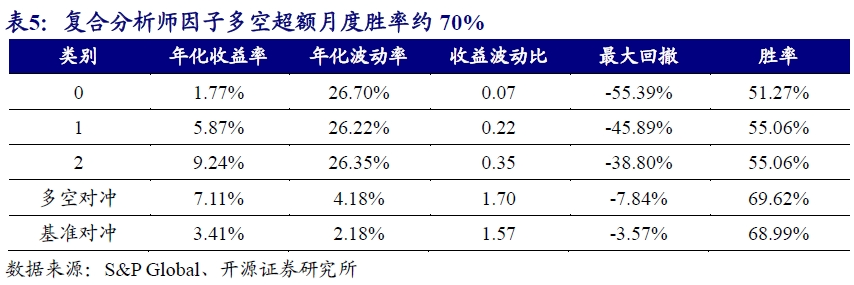
为了更直观感受复合分析师因子的改进,我们对比了其与各单因子在因子预测显著性和稳定性上的差异。复合分析师因子在衡量因子预测显著性的RankIC上有小幅改进,从单因子最高的2.27%提升到2.36%,在衡量因子预测稳健性的RankICIR上从单因子最优的1.34上升到1.65,提升超20%。
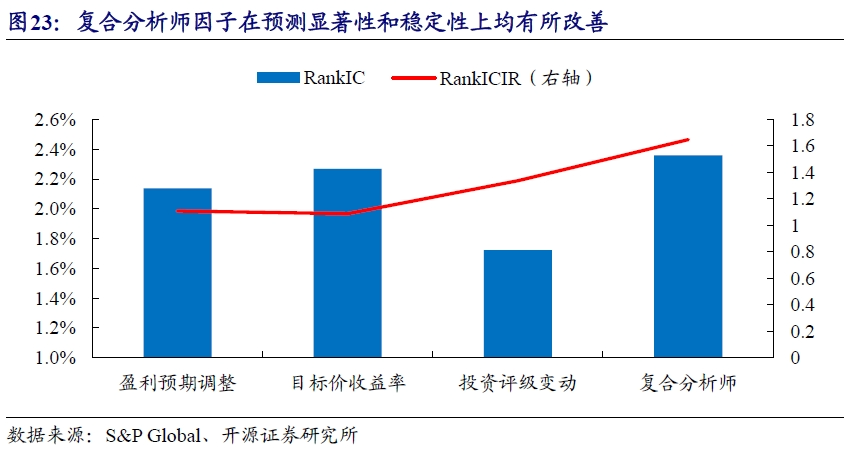
虽然从IC指标上看,每个因子都达不到3%的临界值,但从T值和P值这个维度,每个因子都拒绝没有选股能力的原假设。
04
复合分析师因子的应用
为了更好地控制跟踪误差,我们尝试使用约束优化求解的方式对宽基指数进行增强测试。从前文测试结果可以看出,换手率收敛因子是一个正向因子,因此组合预期收益率最大化等价于因子暴露度最大化。前文中,我们在做因子构建的时候,其实是希望暴露于特定的风格以换取长期的超额表现,如低波和低关注度,因此在约束条件中我们放松对Barra风格的约束。

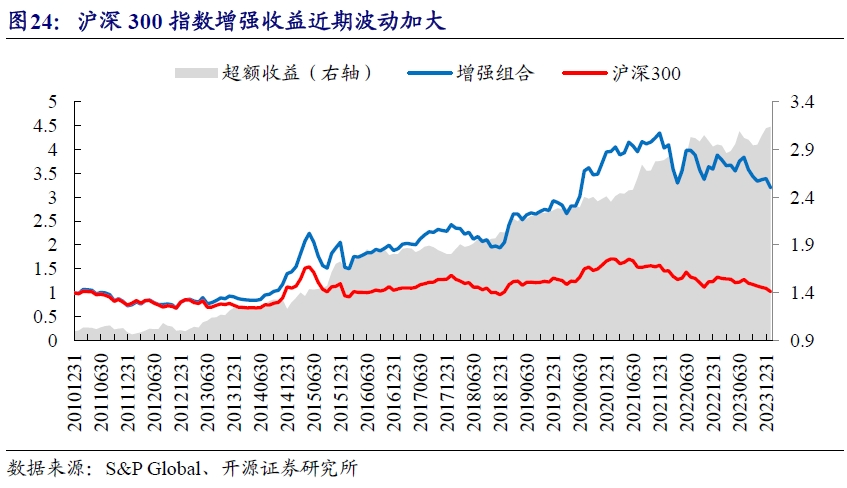
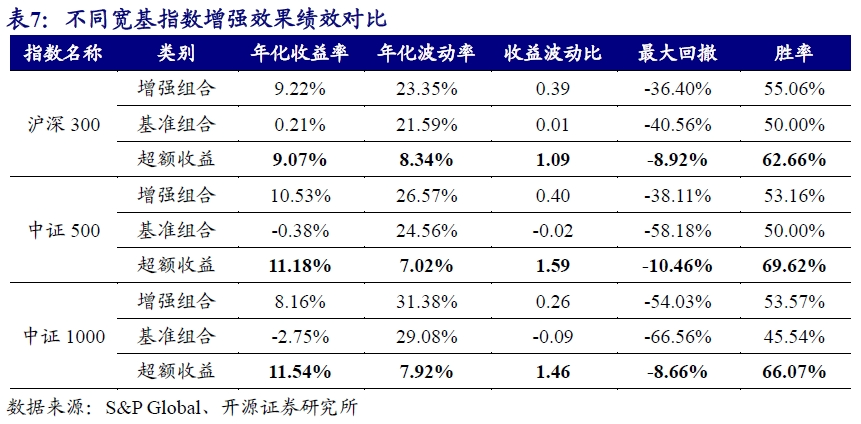
我们分别测算了沪深300、中证500和中证1000指数的增强表现。从测试结果来看,复合分析师因子在不同宽基指数中均有优异的增强效果。沪深300指数增强收益长期来看持续向上,近期波动有所放大。
在中证500指数上,复合分析师因子的增强收益持续上行,但在2019年6月后超额收益出现了持续近一年的回撤。在中证1000指数上,增强组合的超额收益表现稳健。
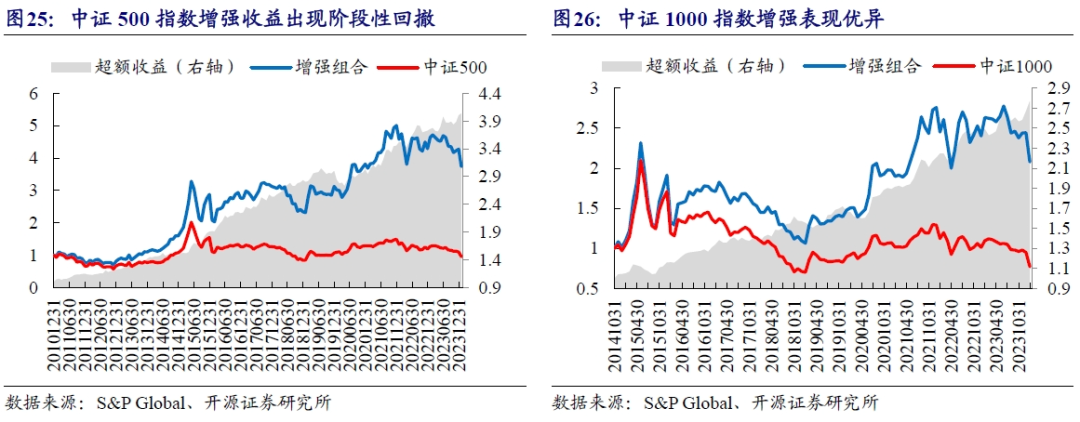
为了直观感受不同宽基指数增强效果的差异,我们统计了不同增强结果的绩效表现。沪深300指数增强年化收益率约9%,中证500指数和中证1000指数有所提升,均超过11%。在超额收益率稳定性上,中证500指数的增强表现最优,收益波动比为1.59,但超额收益率回撤亦是最大水平,达到-10.46%。
05
风险提示
模型测试基于历史数据,市场未来可能发生变化。
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
