
作者:嘟嘟的投研CheatSheet,好投学堂专栏作家
题图:嘟嘟的投研CheatSheet微信公众号
我们的机器学习探索系列从无监督学习的聚类开始(详见《机器学习CheatSheet · 聚类算法》),聚类算法能帮助FOF基金经理快速找到想要的产品(如《基研CheatSheet · 如何挖掘转债公募(附代码)》),对于提升投研效率大有裨益。
接下来让我们进一步深入量化Alpha策略,首先看看适用于量化选股的监督学习算法,包括树模型和神经网络算法等,二者均可用于分类和回归。值得注意的是,此前的聚类算法在机器学习中属于无监督算法。
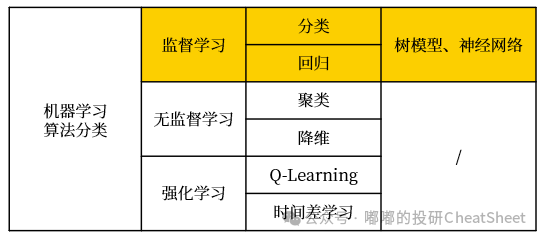
其中,树模型是机器学习算法中经济学解释性最好的,相较于线性模型而言,它可以捕捉解释变量和被解释变量之间的非线性关系。因此,采用了机器学习算法的管理人并非完全是“不可解释的黑箱”。当然,这种解释性也是相对而言的,毕竟当面对上百棵决策树的上百个节点时,也很难弄明白这个树集合(Trees Ensemble)的决策路径是怎样的。
简单概括:在量化选股的预测模型中,树模型整体效果优于神经网络,尤其是在处理基本面因子时,神经网络仅在量价类因子中获得略优于树模型的预测效果。这可能与树模型更擅长处理结构化数据有关,而神经网络通常被认为更擅长处理富文本、图像、音频等非结构化数据。
关于二者的对比,国金的高智威老师有类似的结论可供参考,可以看到基于树模型的CatBoost、DEnsemble、LightGBM和XGBoost整体IC值要优于基于神经网络的GRU、LSTM、TCN和Transformer。
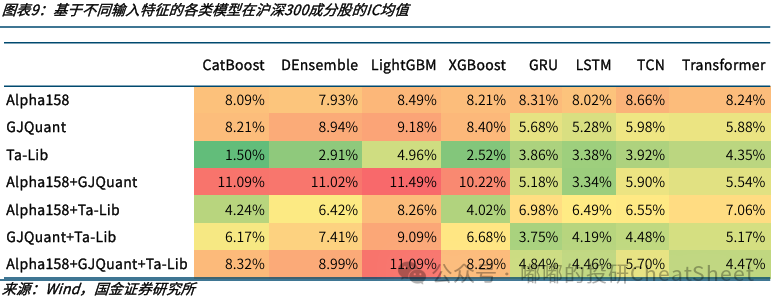
- 注1:CatBoost、DEnsemble、LightGBM和XGBoost都是基于树的模型;而GRU、LSTM、TCN、Transformer则是神经网络模型的代表。
- 注2:Alpha158是微软量化框架Qlib利用量价数据生成的158个因子,GJQuant是国金金工团队依据基本面和日频量价构建的因子,Ta-Lib是用于金融技术分析的开源库。
- 注3:IC值是量化投资中用于评估因子预测能力的重要指标,衡量了因子值与未来收益率的相关程度,取值在-1到1之间,绝对值越大说明预测效果越好。
此外,基于同一大类的不同子算法往往相关性较高,通常能达到0.7-0.9,例如基于树模型的CatBoost、Deep Ensemble、LightGBM和XGBoost。但树模型和神经网络这两个不同大类间的相关性大致只有0.5。因此,可以通过多模型叠加的方式改善组合的收益风险比。
今天先来学习的是量化选股中应用更为广泛的树模型。
树模型的原理
决策树(Decision Tree)是树模型最基础的形态。实际应用中,往往会使用其派生的更复杂模型,如随机森林(Random Forest)、梯度提升树(Gradient Boosting Decision Tree, GBDT)等,以提高模型的准确性和泛化能力。
决策树包括分类树和回归树,在此重点介绍分类树的情况。
简单讲,决策树是使用一些特征值(比如耳朵形状x1、脸型x2、是否有胡须x3……)来进行分类预测(比如这里预测是否为猫)。类似地,我们可以使用一系列基本面和量价类的因子作为特征值,对未来一段时间的涨跌幅排名进行分类预测(如涨幅前30%标记为1,后30%标记为0)。
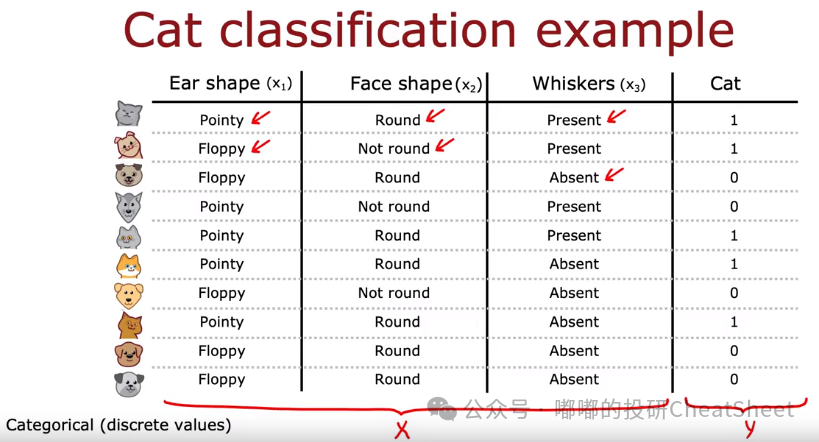
实际上用于预测的决策树形态可以是多种多样的,下图提供了四种预测树:比如最左边的第一棵树,首先判断耳朵形状,如果是圆的就不是猫,如果是尖的则进一步判断是否有胡须,如有则是猫,如无则不是;而最右边的树则是从脸型出发,再去判断耳朵形状,然后去判断是否有胡须。
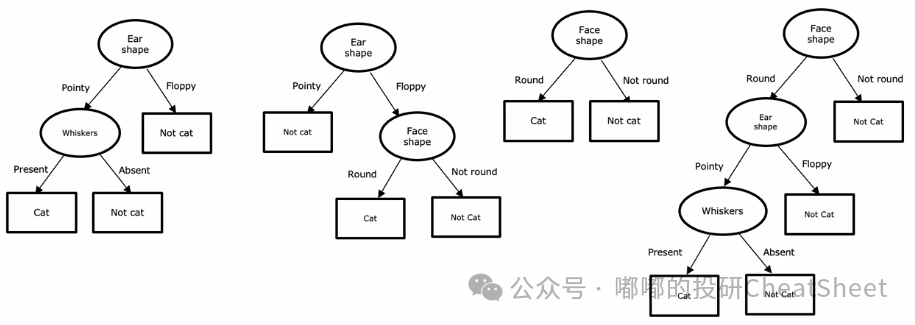
类似地,主观股票基金经理在筛选股票的时候,所考虑的包括估值高低、行业竞争格局好坏、赛道景气高低等,其实放在决策树的框架下也是在模拟类似的决策过程。
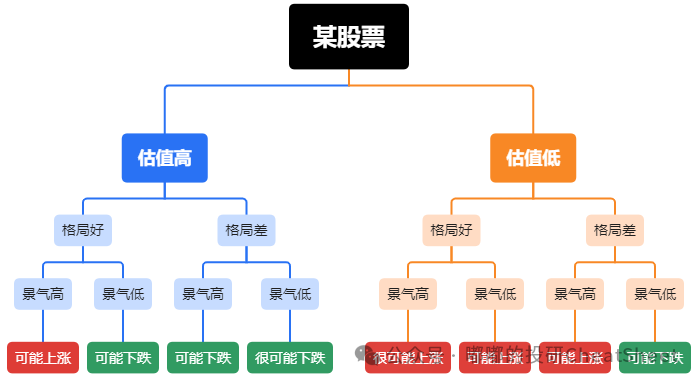
生成决策树的过程
既然在预测同样的事务上(比如猫分类)可以有多种决策树,那么怎么判断哪种树的效果更好、性能更优?这就是决策树的学习过程(Learning Process)。
决策树的学习过程,是为了找到能最大化纯度(Maximize Purity)的树形。那么什么是纯度?它是用来评价决策树在将数据集分割成子集时的效果,即衡量在每个节点上数据的一致性。我们可以通过一个简单的比喻来理解这个概念。假设在分类的过程中,我们得到了如下的五组动物组合,比如第一行的组合全部是狗,最后一行的动物全部是猫,我们就会说这两行组合的纯度很高;反之,如果同一行组合的动物既有猫也有狗,尤其是数量差不多时,比如第三行的各一半,这种就是纯度最低的组合。
在决策树中,我们的目标是通过决策树的分割,使得每个节点上的数据尽可能属于同一类别,也就是说,每个节点的纯度尽可能高。高纯度意味着该节点的数据非常一致,这有助于我们更准确地进行分类或预测。
为了衡量纯度,我们通常会参考几种不同的指标,如基尼不纯度(Gini Impurity)、信息增益(Information Gain)和熵(Entropy)。
比如对于猫分类预测的案例而言,会发现选择耳朵形状作为起始分割点能获得的信息增益是最多的;紧接着再针对树的左右分支,分别再重复(Recursive,递归算法)之前的学习过程(Learning Process),直至达到某个标准,最后就生成了我们想要的决策树。
类似地,在我们的量化选股中,决策树的学习过程就是决定到底是先判断估值高低,还是先判断行业格局,又或者先判断赛道的景气。
简而言之,决策树的生成过程大致遵循几个步骤:1)寻找适合分割的特征;2)根据纯度判断方法,寻找最优分割点,基于该特征把数据分割成纯度更高的两部分;3)判断是否达到要求,若未达到重复步骤1继续分割,直到达到要求为止;4)剪枝以防过拟合。
其中,在纯度判断的过程中,常用的判断方法包括:1)ID3算法,使用信息增益;2)C4.5算法,使用信息增益率;3)CART算法,使用基尼系数。
而在决策树学习过程中,随着子集样本越来越小,纯度必然持续提升,这意味着决策树分割终将走向过拟合。为了降低过拟合风险,需要主动去除一些分类效果不明显的分叉来防止过拟合,这一过程被称为剪枝。
分类树 VS 回归树
以上是关于分类树的介绍,而回归树跟分类树最大的区别,在于预测连续变量而非离散变量。比如在我们量化选股的案例中:
分类树:使用一系列基本面和量价类的因子作为特征值,对未来一段时间的涨跌幅排名进行分类预测(如前30%标记为1,后30%标记为0)。
回归树:使用一系列基本面和量价类的因子作为特征值,对未来一段时间的涨跌幅直接进行回归预测。
如果说分类树生成过程中,追求的是熵最小、信息增益最大,那么回归树的生成过程则是追求方差最小、信息增益最大。
从单一决策树到改进的Ensemble算法
我们前面案例生成的决策树都是单一决策树,但现实中很少使用,因为单一树可能对样本的轻微变化产生过于敏感的反应,如下面的案例,一个样本变化就导致了分割起点的特征发生了变化,原本是使用耳朵形状的,替代样本后就变成了使用胡须,这样的模型具有不稳健的特点,那么该如何改进?

为了提升模型的稳定性,业界想出了使用多个决策树的集合(Trees Ensemble)来替代单一决策树的方法,而多个决策树的生成首先得合成多个样本,通常使用Bootstrap Sampling+Bagging的方法;然后再针对每个样本训练单一决策树,最后通过对它们的决策结果进行投票(对于分类任务)或平均(对于回归任务),从而获得更加准确的结果。这其实就是大名鼎鼎的“随机森林”算法。
随机森林算法是通过“重复抽样”(Bagging)的方式来提高模型的稳定性,而Booosting算法则在此基础之上进一步改进,有针对性的提升上一棵决策树的不足,比如重点针对归类错误的样本来进行训练。
常见的Boosting算法包括GBDT(Gradiant Boosting Decision Tree),该算法是沿着残差减小的方向一步步优化算法,在此基础之上还有更优秀的XGBoost和LightGBM。在实际应用过程中,XGBoost、LightGBM还有CatBoost这几个模型大同小异,重点是弄明白怎么应用。
基于决策树的量化选股框架
在弄明白树模型的原理后,就比较容易理解它是怎么应用到量化选股中的:
首先,构建基于各类基本面和量价的特征因子。可直接借鉴成熟的因子构建体系,如WorldQuant的Alpha 101、国泰君安短周期量价的Alpha 191、微软Qlib中的Alpha 158等;同时将每一期的涨幅数据作为被解释变量进行训练,如果采用分类树的思路,则先将涨跌幅按排名百分比进行分类标记。
其次,便是使用随机森林、XGBoost、LightGBM等算法进行训练,将数据集合分成训练集、验证集和测试集。其中,验证集主要是进行超参的优化,测试集用于观察训练出来的模型在样本外的表现。
最后,便是预测未来某个频率股票的涨跌情况(分类、回归皆可),然后将选股结果放入优化器,以便进行风格、行业、换手等方面的约束,得到优化后的组合。
版权声明:文章版权归原作者所有,部分文章由作者授权本平台发布,若有其他不妥之处的可与小编联系。
